


My p(doom), or, Death by Transformers?
How I've changed my mind over the past years on whether AI will cause the extinction of humanity.

Disclaimer: I am not a technical expert on the field of AI. I’m not actively involved with AI safety, AI governance, or AI capabilities. I am, however, an increasingly informed and concerned philosopher who has spent a few years now hearing about existential risk. Most of the information I have comes from a mix of AI Twitter, blogs, podcasts (like Dwarkesh Podcast), forums (like Effective Altruism Forum, LessWrong, a little of Alignment Forum), and a few academic articles such as Nick Bostrom, Leonard Dung, and others.
In this post, I will be chronicling my intellectual journey regarding the things that have changed my mind on the probability of misaligned artificial superintelligence being likely to extinguish all life on Earth. That is, my intellectual development on these issues, and, later on, the arguments that either raise or lower my confidence of p(doom).
Now, I recognize that it is pretty hard to change somebody’s mind about this topic. It has taken me years of reading, debating, and reflecting to move from a sense of cautious optimism to the sober acknowledgment of the dangers ahead. I hope this post helps illuminate that it has taken me years to digest the arguments, recognize the weaknesses of the position “AI will be aligned to some set of reasonable values by default”, get worried, get stressed, get sad, discuss with other people, and finally be able to “live with it”, that is, live with the fact that technology is, with near certainty, to be what destroys humanity. And, within that, that Artificial Superintelligence is the most likely near-term candidate. This position is held by many prominent figures and researchers, and so it requires serious consideration.
If you want sources for arguments, I can recommend PauseAI’s Learn Section (online), or The Compendium (online, about a two-hours read), or Uncontrollable by Darren McKee (book), or Wait But Why’s short, accessible, though outdated 2015 introduction. For something more advanced, check Yudkowsky’s List of Lethalities.
I won’t be providing many of those arguments here, which I believe has already been done pretty often (although the full argument is dispersed throughout the corners of the internet). This is more like a diary on my intellectual journey about this question. I hope it resonates with others in a similar position.
2016. AlphaGo and casual musings about AGI.
My p(doom) <1%
In 2016, I was doing my undergrad in philosophy and having casual discussions about AI between classes. It was this year when AlphaGo and AlphaZero released, which beat the best grandmasters at Go (an exponentially more complicated game than chess), and the best chess engines at the time, with no sample games and with less than a day of training.
I was much more optimistic about AI capabilities than most of my classmates. I argued that there was nothing in principle that a human could do that future AI wouldn’t be able to do, so the future was in the hands of AI, and I might never get the chance to have a professional career, since AI might do all jobs within a few decades. Overall, it seems to be the path that AI is taking, so I feel vindicated worrying about AI.
However, I wasn’t very worried yet. I thought “A game of Go is relatively simple. It’s still a simple board, so we are decades away from [something along the lines of GPT4].” That’s where I, and many others, would be proven wrong.
2020. Starting to worry about existential risk. Bostrom’s Superintelligence and Toby Ord’s The Precipice.
My p(doom) <1%
Toby Ord’s book, The Precipice, was released when the COVID-19 pandemic started (March 2020). He put the risk of extinction from Artificial Intelligence this century at 10%. He didn’t really provide concrete reasons or arguments why this was his estimate, which I felt was the greatest intellectual weakness of the book. So, when I read this when the book came out, I thought it was an overestimate. My own estimate was closer to less than 1% existential risk from AI.
My reasons were the following:
Like many Effective Altruists, I believed in that AI was far away and that the takeoff would be slow. When Will MacAskill’s What We Owe the Future was released in September 2022, the ideology that was all the rage surrounding it was longtermism, the idea that a greatest amount of the moral value of humanity is located in a far, prosperous future with trillions of people. This ideology made a lot of sense with the implicit assumption, the “vibes”, that smart AI was pretty far away. Well, ChatGPT was released just two months later. This made longtermism seem outdated pretty much at the same time as its key work was released to the wider public. People started suggesting alternative framings, such as “Holy shit, x-risk” as a replacement for the longtermism idea, since now, you, your family, your friends, and everyone else might die from AI within your lifetime. This idea ultimately won the ideological battle around the Effective Altruism and Rationalism spheres.
I finally got around to reading Bostrom’s Superintelligence. But his portrayal of an Artificial Superintelligence seemed complicated. He talked at length about whole brain emulation and other stuff that I thought would be decades or a century away. While we have now mapped a fly’s brain neuron by neuron, the human brain, with 8.6×1010 neurons and 1.5×1014 synapses, with its all its sections and exponential complexity given the great number of connections, has stumped neuroscientists for decades. I thought achieving superhumans via technologies like CRISPR seemed about as likely as developing this type of AI.
The unexpected news was that making a human-level AI is pretty easy, barely an inconvenience. I don’t even know what the engineers at OpenAI are doing, besides stacking more transformers. It seems like half their programming is rendered obsolete by just cranking up the amount of chips. It’s hardware, baby!
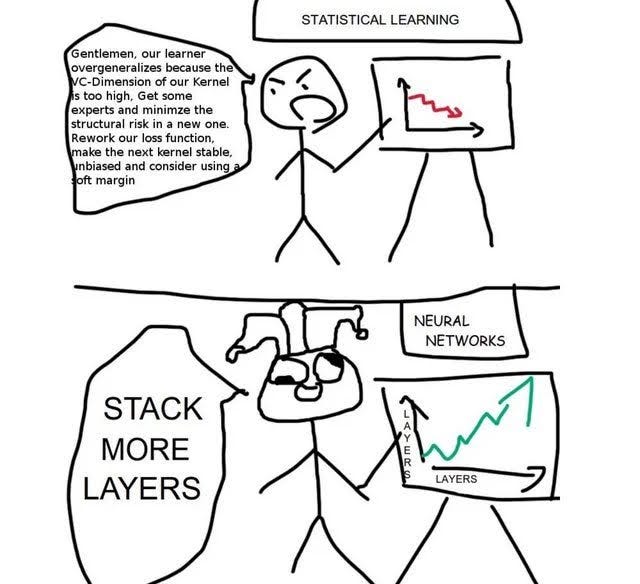
2022. EAG San Francisco and ChatGPT’s release.
My p(doom) = ~1%
Traveling to San Francisco for the first time for EA Global in 2022 gave me a view of a community of people surrounding AI for the first time. However, ChatGPT hadn’t been released yet.
A representative anecdote is the following. I remember talking to Jaime Sevilla over dinner as he was launching EpochAI. I asked him about his AI timelines, and, if I recall correctly, he said something along the lines of “My median is a doubling world economy in terms of GDP growth by 2037”. I was pretty shocked, since my timelines back then were closer to AGI 2050-2070. I remember I told him, “So… should we drop everything to do AI safety?”, in a mix of shock and disbelief. Regarding timelines, I believe now that he was right and I was wrong.
This was also the year that ChatGPT was released. I remember being mind-blown immediately, and I’m still mind-blown with every update that is released (like GPT3 to 3.5, to 4, to DeepSeek, to o1, to o3…). If you knew how archaic AI was before this revolution, you’d be shocked too. The things I would ask of GPT3, from the very beginning, were pretty complicated, such as copyediting my writing, elaborating on my thoughts, or refuting claims from people who I thought were wrong on the internet.
The EA Twittersphere also blew up during this time (with the creation of the iconic figure Qualy the Lightbulb). Engaging with the EA, AI, and rationalist Twitterspheres on the daily has also been very informative and interesting since then. It’s basically been the best source for AI news and opinions, since AI engineers hang out over there, creating a real forum for public discussion.
As you might have noticed, I went from a p(doom) of less than 1% to around 1% during this time.
2024-2025. My Recent Updates.
My p(doom) >10%.
In the past few years, a series of developments have forced me to confront a much bleaker possibility.Here are some of my most recent thoughts that have pushed my p(doom) much higher than ever before, to more than 10%. Since I remember my recent thoughts more accurately, I can now focus on some actual arguments:
We don’t understand AI. Which is the biggest problem with the neural network approach. We don’t know what’s going on inside. We just point towards the results we want to get, and the AI tries over and over until it gets them. We have no idea what makes it get the right answer. There is some interpretability work going on, but it’s heavily behind by several years.
Faster-than-expected AI growth. I think a lot of us agree that the field of AI is growing pretty fast. We have human-level text AI (it thinks faster and better than me in many domains). We have human-level art AI (it definitely draws better than me, and can make animations too). Some of the most mind-blowing results are in Humanity’s Last Exam, which is a collection of difficult questions by field experts.
Alignment-oriented organizations have become evil and corrupt with power. Sam Altman used to be worried about AI existential risk. Anthropic was founded by former OpenAI employees with a stated goal of developing safe, aligned AI systems. But, hearing Dario Amodei’s views on interviews, I’m not sure they’re doing that, honestly. I feel like they’re working on developing the first atom bomb to save us from nuclear war.
AI might have become an international race. China’s DeepSeek has proven it. Countries have bought into the narrative of Leopold’s Aschebrenner Situational Awareness, but we should be careful to buy into such a narrative of racing to be the first with the technology. This is how we all end up dead by an uncontrollable weapon.
Open-Source Models. What do you mean DeepSeek is at the level of o1, is open source, and you can download a model on your computer from a website? That’s how you get other countries closer to catching up in the international race. And that’s how you hand them to North Korea and terrorist organizations for free. Sigh.
We are too damn willing to let AIs do programming. Mark Zuckerberg just said that he’s replacing engineers with AI coders. He also owns Llama, which, although not the most powerful model right now, is pretty powerful, and he feels the threat of falling behind. Honestly? I thought frontier AI companies were more wary and safety-oriented than this. I think this is the kind of behavior that is leading people who are safety-oriented to quit AI labs. This is how you get recursive self-improvement, with an agent that programs itself to do things we don’t understand.
My growing respect for the Internet Rationalists. I used to not see myself as aligned with the Internet Rationalist community. As AI has advanced, I am coming closer and closer to their views. I heavily discounted the Rationalist community, and Eliezer Yudkosky in particular. The first person who changed my view was Connor Leahy, CEO of the AI safety organization Conjecture. His appearance in many videos, interviews, podcasts, and debates has made me more sympathetic to the rationalist position, without the rationalist weirdness and baggage that I found so culturally offputting. I have also grown in appreciation for Eliezer Yudkowsky from hearing him on podcasts (like Dwarkesh, Wolfram, and like five others). Yudkowski is obviously much more prepared and has thought harder about AI safety than his average interlocutors. The podcasts changed my mind about him. It’s actually a bit of a shame that he seems to be debating heavily uninformed people instead of other AI alignment researchers or just top people from AI companies.
I had always heavily discounted Yudkowsky’s opinions because:
He was always wacky and pretty far from the Overton Window. He was pretty weird and eccentric. In my opinion, many rationalists have spent their weirdness points wrong. By wearing a fedora and writing fanfics, he was able to build a community of nerds, but the optics towards the general population suffered as a result. I found his style off-putting and made me think he was closer to fiction than to reality.
He has no academic or industry credentials, and is not very respected in academic circles. Yudkowsky is a high school dropout. And, instead of going to high school, he’s spent decades writing about topics on the internet, such as rationality. He’s incredibly prolific, but in an unfocused way, in my opinion. As a result, it’s hard to “get into” rationalism without investing hundreds of hours consuming their content. This leads to the outside impression of “indoctrination” and “cult”.
Not having the right approach to safety, in my opinion. I think the first-principles approach to things, like decision theory, is a big red herring by Yudkowsky and MIRI that is not very relevant to AI alignment. As a result, the vibe I’m getting is that they’ve pretty much given up on technical AI alignment. It also suggests to me that we need a hands-on approach on the models themselves if we want the technical stuff to work.
Nevertheless, I've now started recognizing my prejudice and now I see Yudkowsky and other Rationalists as ahead of the curve regarding AI risk, even if I think they might be wrong on the specifics.
Anyway, here is the key argument that most recently changed my mind. What I was missing was the last premise, the last piece of the puzzle:
(OLD) Human intelligence is not the ceiling of intelligence. Or, as Bostrom puts it: “Far from being the smartest possible biological species, we are probably better thought of as the stupidest possible biological species capable of starting a technological civilization – a niche we filled because we got there first, not because we are in any sense optimally adapted to it.”
Intelligence is like the second picture, not the first:

How people typically think intelligence works. 
How machine superintelligence might work. (OLD) AI is likely to optimize to an arbitrary goal. That is, Instrumental Convergence, commonly known as the paperclip maximizer argument. The idea is that an agent with a final goal will acquire the sub-goals of acquiring intelligence, resources, self-preservation, and improving their capabilities, because these subgoals help them achieve pretty much any final objective. While Bostrom skips a few steps, here it goes: “Suppose we have an AI whose only goal is to make as many paperclips as possible. The AI will realize quickly that it would be much better if there were no humans because humans might decide to switch it off. Because if humans do so, there would be fewer paperclips. Also, human bodies contain a lot of atoms that could be made into paperclips. The future that the AI would be trying to gear towards would be one in which there were a lot of paperclips but no humans.”
(OLD) AI minds are likely to be “alien” minds, since they don’t have the same biological drives as animals.
(OLD) The Orthogonality Thesis, that levels of intelligence are uncorrelated with morality. That is, you can have an AI that is: Good/Smart, Good/Dumb, Evil/Smart, or Evil/Dumb combinations. Intelligence doesn’t ensure morality. So far, we have created Good/Dumb with current models like ChatGPT, and Evil/Dumb models (such as GPT model that suffered from the Waluigi Effect).
(OLD) We only got one shot. If we go extinct, there’s no going back and trying again.
(NEW) The space of possibilities that is compatible with life is very narrow. Life needs an environment with raw materials, food, shelter, water, etc. For humans to flourish, we need more than that, we basically need to be the top dominant species to take anything we want out of nature, rather than being prohibited by a force stronger than ourselves. I think this “narrow band of possibilities” aspect is an underrated or often-ignored aspect of Yudkowski’s doomerism, that I hadn’t fully grasped before. This realization is what has raised my p(doom) the most in the past few months.
About a month ago I had the sudden realization that we might be fucked.


So if I think this line of argument of “business as usual” might lead us to extinction, what keeps my p(doom) as not ensuring the destruction of all life?
AGI to ASI hasn’t happened yet, which is weird. I think even Yudkowski admits that we live in a weird timeline. If his predictions of hard takeoff had been correct, a slightly beyond human-level AGI (like GPT4) would have jumped into a Superintelligence in a matter of seconds or days, and destroyed humanity in a short time. The reality? Well, we have an AI that is way better than me at stuff like math, programming, and pretty much every field in which I’m not an expert, yet we don’t have killer superintelligence. This is a point against AI doomers’ models of the world.
ASI will get bottlenecked. The way we are obtaining AI is more hardware-intensive and less software-intensive than we predicted. Before ChatGPT, I thought AI would be mainly a matter of software, and that the risk would be that it would spread itself to all our computers, phones, and other devices like a virus. Turns out that programmers are shittier than expected, and that hardware is magic. “Stack more transformers” is the name of the game. That means ASI needs energy and chips. Unless we get big energy efficiency gains (which I don’t fully discount, look at DeepSeek), ASI is going to have an issue with getting the nuclear power plants and Nvidia chips required for its recursive self-improvement.
We might be able to use AI for alignment purposes. That is, using GPT4 to align GPT5, then GPT5 to align GPT6, etc. This argument is the bane of Yudkowski, because the AI might betray us along the way, but I think it deserves credit, if achieving Superhuman levels is slow.
We’re modeling the whole situation wrong. Turns out that the arguments about Orthogonality Thesis, Instrumental Convergence, etc. are not cutting reality at its natural joints. Remember, our model of reality is not, and will never be, reality itself. The real world will likely surprise us.
For other reasons, see here, pictured below:


The Future (2025-2026)
My p(doom) >30%?
O crystal ball, o crystal ball, what does the near future hold?
Well, Nvidia is currently the highest valued company in the world, at more than $3 trillion valuation, which is clearly in great part because Nvidia is the main provider of chips for AI. This means that a lot of the world’s economy is heavily watching AI, and they’ll want results.
Stargate. 500 billion towards AI, which means 2% of the US’ GDP going towards AI. This is because Sam Altman and others are selling Donald Trump that AI will cure cancer, speed up technological progress, achieve military objectives, etcetera. This means that Altman and others are under pressure to deliver results during Trump’s term (2025-2029).
Perhaps I should be a magical future-proofed bayesian and if I think that future evidence will lead me to conclude that risk is >30%, so I should update now. But I don’t know, I just lack evidence or powerful arguments one way or the other, and vibes can be misleading. I’m also aware that I’m in an internet echo chamber of people who are worried about AI risk. So let me sit on a vague “>10%” for now.
Possibility of p(doom) = >95%?
Still, I’ve been worried for years that nothing saves us from a fuck-up later, unless we establish ASI surveillance.
Imagine AI alignment goes right. It doesn’t really matter why. Here’s an argument, in my opinion, for why humanity might be doomed for extinction anyways:

Even if we get aligned ASI, I’m worried that this means that the country that gets to ASI first will have to establish some form of ASI totalitarianism, which prevents any other countries from reaching it, in case it is misaligned. Yudkowsky expresses similar worries:

And Bostrom too, in his Vulnerable World Hypothesis, “the hypothesis is that there is some level of technology at which civilization almost certainly gets destroyed unless quite extraordinary and historically unprecedented degrees of preventive policing and/or global governance are implemented.”
He goes on to argue that we might need extreme levels of global coordination, or policing and surveillance measures to prevent extinction due to risky technology.
Another way, I think, is to get the ASI to hack into all of the world’s computers, locking out everyone else in the world from programming anything like a misaligned Superintelligence ever again.
It sounds a bit depressing to think that this might be “the good scenario” where we all survive. It might involve some extreme level of surveillance or a world government. Still, much better than literal extinction.
Conclusion, and a Call to Action.
Each year worries me more than the last. I really hope AI gets bottlenecked hard or a mediocre AGI fires some big-but-failed warning shot, and that governments take swift action regulating AI as a result.
Let’s heavily slow the development of more and more powerful AI models until we’re more caught up with AI alignment and we’re not facing an existential threat. In the meantime, we can make useful wrappers for our decent Large Language Models and reap the rewards.
Check PauseAI and other sources. Learn a bit about this topic. Subscribe to their newsletter. Try to keep up with their news. Email your local political representative that AI risk is not a joke sci-fi scenario, but a real risk that the Nobel Prize founding fathers of AI have quit their companies over. The point of contacting your political representative is so that you plant the worry on their minds. Perhaps you won’t change their minds today, but at least they’ll be prepared to accept to change their minds once they start getting lots of calls because something big happened in the near future.
Keep an eye open for Open Letters to sign about AI. For example, the Future of Life Institute Open Letter on 6-months AI moratorium. Keep an eye out for similar letters to sign.
Attract talent to AI safety, and away from AI capabilities. Sadly, most money seems squarely within AI capabilities.
I’m running out of ideas, so here’s more advice for what you can do.
Finally, well, if we die by Superintelligence, I hope it will be unexpected and swift. It was a wild ride, but we were too ambitious for our own good. Icarus flew too close to the sun. In that last breath, we’ll learn what The Great Filter was.
But we shouldn’t go without a fight.
I am more optimistic than you for a few reasons, but one that I'd like to highlight is that I think humans are likely okay in a world with mostly aligned ASIs but also some misaligned ones. In that case there will be much more intelligence and resources working in favor of humanity than against. This is far from perfect of course, since some technologies have much easier offence than defence. It's easier to create a novel pathogen than to defend against one. But in a world where most AI is aligned, it seems very likely that some humans will survive even in a worst-case engineered pandemic.
This was a good piece and largely mirrors my own evolution on this question. For me, it was Zvi who flipped my thinking with the disempowerment thesis, which I find too highly plausible. Single metric, bayesian priors, have always struck me as an overly narrow frame, but it looks like LLMs think very much like Rationalists, maybe good maybe bad, but narrowing for sure. One thing to look at though, and people hate me for saying this, but Grok is the first next-FLOP-gen model. And while people are praising it for being 'open' and non-refusal, it's not **that much better** than the previous O1 (GPT 4 + Thinking) generation. Unverifiable tasks might be a bigger gap in the jagged frontier than we assume. p(doom) 10-15% depending on definition.